
竞赛题干与数据来源于$\textrm{ECNU}$《数据挖掘》课程。
开放下载:数据与模型、$\textrm{KDD}$基准系统描述、$\textrm{KDD}$竞赛任务和数据集描述
实验环境:
- 操作系统:$\textrm{Win10}$
- 实验语言:$\textrm{Python3.9}$,$\textrm{C}$++$\textrm{11 with g}$++ $\textrm{Compiled}$
- 编译环境:$\textrm{VsCode with command line}$
1. 安装用包
0安装需要用到的包:$\textrm{numpy}$,$\textrm{pandas}$,$\textrm{sklearn}$,$\textrm{PyPrind}$
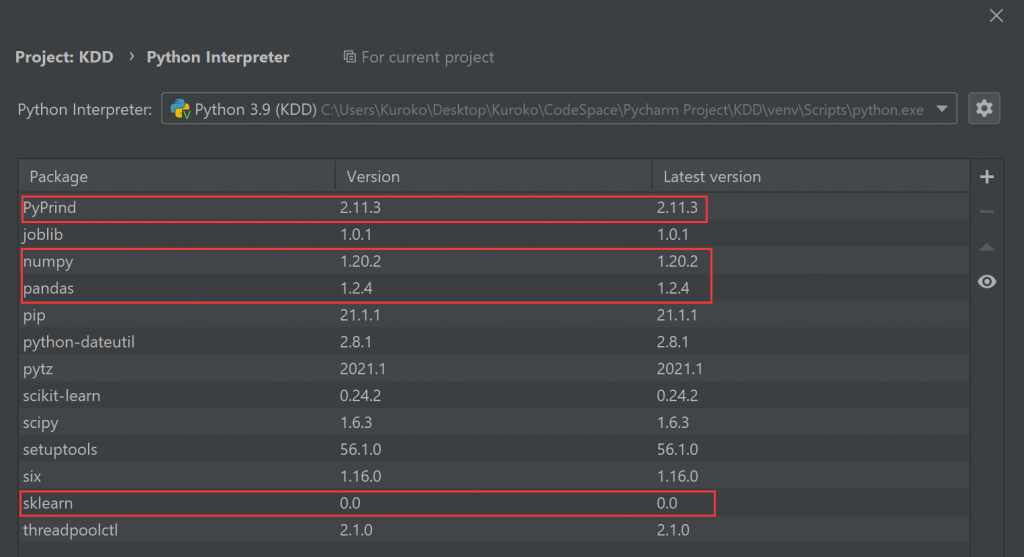
2. 运行系统
运行$\textrm{model_trainer\trainer.py}$文件:如图报错

原因分析:在$\textrm{windows}$系统当中读取文件路径可以使用$\textrm{\\}$,但是在$\textrm{python}$字符串中$\textrm{\\}$有转义的含义,如$\textrm{\\t}$可代表$\textrm{TAB}$,$\textrm{\\n}$代表换行,所以需要采取一些方式使得$\textrm{\\}$不被解读为转义字符。
解决方案:在$\textrm{CWD}$前面加字母$\textrm{r}$保持字符原始值的意思

再次报错:认为$\textrm{encoding}$是无效参数

搜索解决方案:使用$\textrm{pip install requests --upgrade}$更新$\textrm{request}$
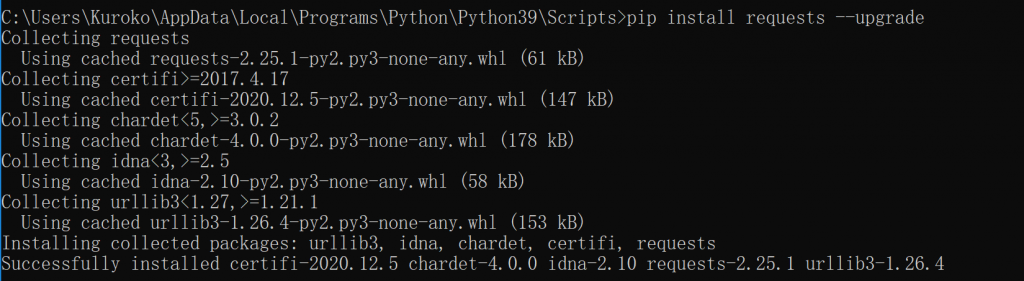
结果并没有什么用
解决方案$\textrm{2}$:直接删去$\textrm{encoding='utf-8'}$参数

可以正常运行
解决方案$\textrm{3}$:把$\textrm{encoding='utf-8'}$参数改放在里面一层括号内,也可以正常运行。


3. 系统介绍
$\textrm{KDD_Benchmark}$:基准系统目录
- $\textrm{data}$:数据目录
- $\textrm{dataset}$: 数据集目录
- $\textrm{train_set}$: 训练集文件夹
- $\textrm{Train.authorIds.txt}$: 训练集的所有作者列表
- $\textrm{Train.csv}$:训练集
- $\textrm{valid_set}$: 验证集文件夹
- $\textrm{Valid.authorIds.txt}$: 验证集的所有作者列表
- $\textrm{Valid.csv}$:验证集
- $\textrm{Valid.gold.csv}$:验证集的标准答
- $\textrm{test_set}$: 测试集文件夹
- $\textrm{Test.authorIds.txt}$: 测试集的所有作者列表
- $\textrm{Test.csv}$:测试集
- $\textrm{Author.csv}$: 作者数据集
- $\textrm{coauthor.json}$: 共作者数据
- $\textrm{Conference.csv}$: 会议数据集
- $\textrm{Journal.csv}$: 期刊数据集
- $\textrm{Paper.csv}$:论文数据集
- $\textrm{PaperAuthor.csv}$: 论文-作者 数据集
- $\textrm{paperIdAuthorId_to_name_and_affiliation.json}$:包含论文-作者对 $\textrm{(paperId,AuthorId)}$与 名字-单位$\textrm{(name1##name2; aff1##aff2)}$的映射关系
- $\textrm{feature}$: 特征文件夹
- $\textrm{train.feature}$: 存放训练数据集抽取得到的特征
- $\textrm{test.feature}$: 存放测试数据集抽取得到的特征
- $\textrm{model}$: 模型文件夹
- $\textrm{kdd.model}$:训练好的分类模型
- $\textrm{model_trainer}$: 训练模型
- $\textrm{coauthor.py}$: 获取共作者
- $\textrm{data_loader.py}$: 加载数据
- $\textrm{evalution.py}$: 评估脚本
- $\textrm{feature_functions.py}$: 特征函数
- $\textrm{make_feature_file.py}$: 生成特征文件
- $\textrm{stringDistance.py}$: 获取字符串距离信息
- $\textrm{trainer.py}$: 模型训练器,主函数
- $\textrm{predict}$: 预测结果文件夹
- $\textrm{test.predict}$: 转化为 $\textrm{KDD}$提交格式的测试结果
- $\textrm{test.result}$:模型的直接预测结果
- $\textrm{authorIdPaperId.py}$: (作者,论文) 对类定义
- $\textrm{classifier.py}$: 分类器,使用了策略模式。
- $\textrm{config.py}$:配置文件
- $\textrm{confusion_matrix.py}$: 评估脚本所使用的包
- $\textrm{example.py}$: 样本类定义
- $\textrm{feature.py}$:特征类定义
- $\textrm{README.md}$: 说明文件
- $\textrm{test.py}$:测试文件
- $\textrm{util.py}$: 小工具类
4. 数据文件
4.1 Author.csv
作者数据集,包含了作者的编号,姓名和隶属单位:
![]()
其中描述文件说明:相同的作者可能在数据集中出现多次,因为作者在不同会议/期刊上发表论文的名字可能有多个版本。如$\textrm{J.Doe,Jane Doe,J.A.Doe}$均指同一个人,此外,$\textrm{Affiliation}$ 信息可能为空。因此为了检测本次文件中是否存在这样的情况,以及$\textrm{Id}$是否可以作为区分作者的主键,撰写如下$\textrm{C}$++代码。
辅助文件$\textrm{0}$:$\textrm{KDD_Benchmark\\auxiliary_file\\Author.cpp}$
代码流程为:
- 获取当前路径,剪枝后半部分再附加数据文件名获取数据路径
- 依次读入每一条数据,以$\textrm{Id}$为键,以$\textrm{Name}$为值存入哈希表中
- 哈希表的数据类型是$\textrm{<int,vector<string>>}$
- 遍历哈希表,检查是否有某个$\textrm{id}$的$\textrm{vector.size()>1}$,即含有多个名字
- 最终输出为空,说明当作者以不同格式的名字出现时,所拥有的$\textrm{Id}$值并不相同
# include <iostream>
# include <fstream>
# include <cstdlib>
# include <sstream>
# include <unordered_map>
# include <vector>
using namespace std;
/*
* Author.cpp
* Written by Kuroko on May 12th in 2021
* This is a auxiliary file to ensure
* whether an author's name may appear
* more than once in different forms.
* If so, will they have the same id value?
* standard = c++11, compiled with g++
* Opearting System = Win10
*/
string getDataPath(string path)
{
stringstream ss;
string WD = _pgmptr,s; //to get the present directory
int count = 0;
while(WD.find("\\") != string::npos)
{
WD.replace(WD.find("\\"),1," ");
count++;
}
ss<<WD;
WD.clear();
for(int i = 0;i < count-1;i++)
{
ss>>s;
WD += s+"\\";
}
WD += path;
return WD;
}
int main(void)
{
stringstream ss;
string line,key,value,tmp;
string dataPath = getDataPath("data\\dataset\\Author.csv");
ifstream inStream(dataPath,ios::in);
unordered_map<int,vector<string>> dict;
getline(inStream,line);
while(getline(inStream,line))
{
key = line.substr(0,line.find(","));
line = line.substr(line.find(",")+1);
value = line.substr(0,line.find(","));
dict[stoi(key)].push_back(value);
}
for(auto it = dict.begin();it != dict.end();it++)
{
if(it->second.size() > 1)
{
cout<<it->first<<":{";
for(int i = 0;i < it->second.size();i++)
cout<<it->second[i]<<(i==it->second.size()-1?"}\n":",");
}
}
return 0;
}
考虑到整个$\textrm{KDD}$系统是$\textrm{Python}$代码,因此撰写了$\textrm{Python}$版本的,篇幅短了许多,但是执行一次的时间$\textrm{(13s)}$大概是$\textrm{C}$++$\textrm{(0.3s)}$的$\textrm{40}$倍。后续数据处理中因为$\textrm{csv}$文件时以逗号进行表格分隔的,而有些字段值本身也会包含逗号,因此就用引号包住,在用$\textrm{C}$++读入数据的时候则需要用状态机来读取,较为麻烦,因此还是调用$\textrm{Pandas}$库处理$\textrm{csv}$数据。
辅助文件$\textrm{1}$:$\textrm{KDD_Benchmark\\auxiliary_file\\Author.py}$
# KDD_Benchmark\auxiliary_file\Author.py
# encoding: utf-8
import os
import sys
import importlib
from pandas import Series, DataFrame
import pandas as pd
importlib.reload(sys)
sys.path.append("../")
import config
if __name__ == '__main__':
author_file_path = os.path.join(config.DATASET_PATH,"Author.csv")
data = pd.read_csv(author_file_path, encoding='utf-8')
dic = {}
for i in range (len(data)):
id = data.loc[i]["Id"]
if id in dic:
dic[id].append(data.loc[i]["Name"])
else:
dic[id] = [data.loc[i]["Name"]]
for e in dic:
if len(dic[e]) > 1:
print(e,":",dic[e])
4.2 Paper.csv
论文数据集,包含了论文的标题,会议/期刊信息,关键字。因为同一论文可能从不同的来源获取,因此$\textrm{Paper}$可能会存在多个副本,此外,$\textrm{Keyword}$信息可能为空。
![]()
同样撰写辅助文件,判断是否存在多个副本的论文,可选择性写入整理后文件。
辅助文件$\textrm{2}$:$\textrm{KDD_Benchmark\\auxiliary_file\\Paper.py}$
代码流程为:
- 认定副本论文之间$\textrm{Id}$相同
- $\textrm{dataFrame}$调用$\textrm{sort_values}$以$\textrm{Id}$进行排序
- $\textrm{reset_index}$重新索引
- 遍历整个$\textrm{dataFrame}$,查看相邻项之间是否有$\textrm{Id}$值相同的情况
- 文件执行时间较长(大概需要$\textrm{5}$分钟),结果为没有出现相同的$\textrm{Id}$值
# KDD_Benchmark\auxiliary_file\Paper.py
# encoding: utf-8
import os
import sys
import importlib
import numpy as np
from pandas import Series, DataFrame
import pandas as pd
importlib.reload(sys)
sys.path.append("../")
import config
if __name__ == '__main__':
paper_file_path = os.path.join(config.DATASET_PATH,"Paper.csv")
data = pd.read_csv(paper_file_path, encoding='utf-8')
data = data.sort_values(by = "Id")
data = data.reset_index(drop = True)
print(data.head())
vis = np.zeros(len(data))
for i in range(1,len(data)):
print(i)
if data.loc[i]["Id"] == data.loc[i-1]["Id"]:
if vis[i-1] == 0.0:
print(data.loc[i-1])
vis[i-1] = 1
if vis[i] == 0.0:
print(data.loc[i])
vis[i] = 1
#data.to_csv("PaperWithIdSorted.csv",index=False)
将$\textrm{line15}$与$\textrm{line21}$的$\textrm{Id}$替换为$\textrm{Title}$,以论文关键词进行排序查找来查看是否有论文存在副本。
结果发现大量相同的和相似的论文标题,由此得出结论,同一论文出现在来自不同来源的的时候,$\textrm{Id}$值是不同的,至于大量相似标题的论文,还需要借助其他文件和算法来进一步确定。
4.3 PaperAuthor.csv
(论文,作者)数据集,包含(论文$\textrm{Id}$-作者$\textrm{Id}$)的$\textrm{pair}$信息。该数据集包含噪声——不正确的$\textrm{pair}$对,即文件中包含的作者不一定写了对应的论文。原因是,作者名字存在歧义,可能存在同名的不同人或者作者名字有多个版本。例如,在$\textrm{Author.csv}$文件中存在以下四条记录:
![]()
以上四条记录可以表示$\textrm{1,2,3,4}$个作者,既可能指向同一个人,也可能指向四个人,于是当在$\textrm{PaperAuthor.csv}$文件中出现$\textrm{1}$号作者写了论文$\textrm{X}$的时候,可能也会写入$\textrm{(2,X),(3,X),(4,X)}$的对从而造成错误冗余。事实上,在本次数据文件中,大量论文都指向了多个作者(后来得知还有联合创作的设定)。
不过在$\textrm{PaperAuthor.csv}$文件中,还包含了作者的额外信息,同样,隶属单位信息可能为空。
![]()
到目前为止,数据中表现出来的问题有
- 作者多名,且不同形式下的名字编号与名称均不同,隶属单位可以作为辅助判断信息但不能充当唯一依据,且隶属单位还有可能为空。
- 论文多副本,不同副本下的编号均不同,标题可能相同或近似,也有可能差异较大,年份与论文关键词可以辅助,但同样不能完全解决问题且关键字可能为空。
- 论文与作者的匹配对中本身就含有噪声,还要考虑论文的多副本与作者的多形式。
4.4 Conference.csv & Journal.csv
会议和期刊数据集,每篇论文发表在会议或者期刊上:
![]()
关于这两个数据集的描述中,暂时没有提到有关噪声和缺失的问题,但直观上看,该数据集与解决$\textrm{4.3}$提出的问题也没有任何帮助。
4.5 coauthor.json
共同作者的信息,通过$\textrm{KDD_Benchmark\\model_trainer\\coauthor.py}$代码从$\textrm{Author.csv}$文件中集成出来,其算法为:
- 字典作为统计容器
- 当出现形如$\textrm{(1,X),(2,X),(3,X),……,(n,X)}$的数据时,认为$\textrm{(1,2,3,……,n)}$合作写了一次论文$\textrm{X}$
- 将$\textrm{(1,2),(1,3),……(1,n),(2,1),(2,3),……(2,n),……(n,1),(n,2),……(n,n-1)}$写入字典
- 然后通过$\textrm{Counter}$库统计出合作次数做高的$\textrm{k(default=10)}$的作者
- 可以在$\textrm{coauthor.py}$的$\textrm{main}$函数部分修改$\textrm{k}$的值来重新生成文件\
辅助文件$\textrm{3}$:$\textrm{KDD_Benchmark\\auxiliary_file\\get_coauthor.py}$
# KDD_Benchmark\auxiliary_file\get_coauthor.py
# encoding: utf-8
import os
import sys
import importlib
import json
importlib.reload(sys)
sys.path.append("../")
import config
if __name__ == '__main__':
coauthor_file_path = os.path.join(config.DATASET_PATH,"coauthor.json")
coauthor = json.load(open(coauthor_file_path))
while True:
try:
authorId = input()
if authorId.isdigit():
print(coauthor[authorId])
else:
break
except:
break
通过输入作者$\textrm{Id}$可以获得与该作者合作次数最多的$\textrm{k}$个作者,输出格式如下

该输出表示编号为$\textrm{742736}$的作者与编号为$\textrm{2182818}$的作者合作了$\textrm{7}$次,与编号为$\textrm{1108518}$的作者合作了$\textrm{3}$次,以此类推。
4.6 paperIdAuthorId_to_name_and_affiliation.json
在$\textrm{PaperAuthor.csv}$,除了出现错误的配对噪声之外,还有可能出现同一个出现重复的(论文$\textrm{Id}$,作者$\textrm{Id}$),而$\textrm{name}$属性和$\textrm{affiliation}$属性不相同,如$\textrm{(X,1,Alice.Bob,ECNU),(X,1,A.B,East China Normal University)}$,于是希望将这些项进行合并成形如$\textrm{\{(X,1): Alice.Bob##A.B,ECNU##East China Normal University)\}}$的格式,$\textrm{paperIdAuthorId_to_name_and_affiliation.json}$就是合并的结果,该文件通过$\textrm{KDD_Benchmark\\model_trainer\\stringDistance.py}$代码从$\textrm{PaperAuthor.csv}$文件中集成出来。
# KDD_Benchmark\auxiliary_file\pana.py
# encoding: utf-8
import os
import sys
import importlib
import json
importlib.reload(sys)
sys.path.append("../")
import config
if __name__ == '__main__':
pana_file_path = os.path.join(config.DATASET_PATH,"paperIdAuthorId_to_name_and_affiliation.json")
print("Loading...")
pana = json.load(open(pana_file_path))
print("Finished!")
while True:
try:
pa = input()
if pa.count("|") == 1:
paperId,authorId = pa.split("|")
if paperId.isdigit() and authorId.isdigit():
print(pana[pa])
else:
break
else:
break
except:
break
通过输入$\textrm{PaperId|AuthorId}$来获取关于该$\textrm{pair}$对的全部$\textrm{name}$和$\textrm{affiliation}$,输出格式如下:

该输出表示编号为$\textrm{1156615}$的论文与编号为$\textrm{2085585}$的作者同时包含两个名为$\textrm{Hang Li}$的作者(是否是同一人还不能确定),两位作者分别隶属于华为与微软。
4.7 Train.csv
训练集文件,格式如下:
![]()
其中$\textrm{ComfirmedPaperIds}$列对应的表示该作者写了这些论文的列表,$\textrm{DeletedPaperIds}$列对应的表示该作者没有写这些论文的列表。
4.8 Valid.csv
验证集,格式如下:
![]()
4.9 Valid.gold.csv
验证集的标准答案,文件格式与训练集$\textrm{Train.csv}$相同,用户需要完成的工作就是将$\textrm{PaperIds}$划分成$\textrm{ComfirmedPaperIds}$和$\textrm{DeletedPaperIds}$并写入预测结果$\textrm{test.predict}$当中,然后调用$\textrm{KDD_Benchmark\\model_trainer\\evaluton.py}$用形如$\textrm{python evalution.py gold_file_path pred_file_path}$的命令来获取评测结果。
4.10 其他文件
对于测试集文件夹$\textrm{test_set}$在公布竞赛数据之前为空白状态,用户通过验证集进行测试,不断完善系统来提高评测结果的准确率,当测试文件发布后,用户将调用设计好的系统来生成测试集预测结果,文件格式与验证集标准答案相同,但用户没有标准答案来获取评估结果,因此要设计一个均衡的模型,不能只针对验证集调参导致过拟合。
在训练集,测试集和验证集下,都还有一个$\textrm{.txt}$的文本文件,包含了在训练集/测试集/验证集中涉及到的全部作者$\textrm{Id}$,用户可根据这些$\textrm{Id}$进行模型调整。
4.11 数据规模
![]()
5. 源代码
5.1 __init__.py
初始化文件,在本系统中为空
5.2 config.py
配置文件,定义了大量文件的绝对路径,在剩余文件中均有引用
#!/usr/bin/env python
#encoding: utf-8
import os
import socket
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
# 当前工作目录,最后指向KDD_benchmark即可
#CWD = "/home/username/KDD/KDD_benchmark" # Linux系统目录
CWD = r"C:\Users\Kuroko\Data-Mining\KDD\KDD_Benchmark" # Windows系统目录
DATA_PATH = os.path.join(CWD, "data") #~\KDD_Benchmark\data
DATASET_PATH = os.path.join(DATA_PATH, "dataset") #~\KDD_Benchmark\data\dataset
# 训练和测试文件(训练阶段有验证数据,测试阶段使用测试数据
#~\KDD_Benchmark\data\dataset\train_set\Train.csv
#~\KDD_Benchmark\data\dataset\valid_set\Valid.csv
#~\KDD_Benchmark\data\dataset\valid_set\Valid.gold.csv
TRAIN_FILE = os.path.join(DATASET_PATH, "train_set", "Train.csv")
TEST_FILE = os.path.join(DATASET_PATH, "valid_set", "Valid.csv")
GOLD_FILE = os.path.join(DATASET_PATH, "valid_set", "Valid.gold.csv")
# 模型文件, ~\KDD_Benchmark\model\kdd.model
MODEL_PATH = os.path.join(CWD, "model", "kdd.model")
# 训练和测试特征文件, ~\KDD_Benchmark\feature\train.feature&test.feature
TRAIN_FEATURE_PATH = os.path.join(CWD, "feature", "train.feature")
TEST_FEATURE_PATH = os.path.join(CWD, "feature", "test.feature")
# 分类在测试集上的预测结果,~\KDD_Benchmark\predict\test.result
TEST_RESULT_PATH = os.path.join(CWD, "predict", "test.result")
# 重新格式化的预测结果, ~\KDD_Benchmark\predict\test.predict
TEST_PREDICT_PATH = os.path.join(CWD, "predict", "test.predict")
#共作者数据文件, ~\KDD_Benchmark\data\dataset\coauthor.json
COAUTHOR_FILE = os.path.join(DATASET_PATH, "coauthor.json")
#姓名和单位的整合后文件 ~\KDD_Benchmark\data\dataset\paperIdAuthorId_to_name_and_affiliation.json
PAPERIDAUTHORID_TO_NAME_AND_AFFILIATION_FILE = os.path.join(DATASET_PATH, "paperIdAuthorId_to_name_and_affiliation.json")
#论文-作者对文件 ~\KDD_Benchmark\data\dataset\PaperAuthor.csv
PAPERAUTHOR_FILE = os.path.join(DATASET_PATH, "PaperAuthor.csv")
#作者信息文件 ~\KDD_Benchmark\data\dataset\Author.csv
AUTHOR_FILE = os.path.join(DATASET_PATH, "Author.csv")
5.3 authorIdPaperId.py
# KDD_Benchmark\authorIdPaperId.py
# 将 (AuthorId, PaperId) 设计成类,表示要训练/预测 的样本
class AuthorIdPaperId(object):
def __init__(self, authorId, paperId):
self.authorId = authorId
self.paperId = paperId
self.label = None # 类标
5.4 data_loader.py
将训练集,验证集和测试集转换为$\textrm{AuthorIdPaperId}$类结构并以列表的形式返回。
#KDD_Benchmark\model_trainer\data_loader.py
#!/usr/bin/env python
#encoding: utf-8
# import sys
# sys.setdefaultencoding('utf-8')
from authorIdPaperId import AuthorIdPaperId
import util
# 加载训练数据
def load_train_data(train_path):
#加载训练集Train.csv
data = util.read_dict_from_csv(train_path)
authorIdPaperIds = [] #存储AuthorIdPaperId类的列表
#枚举训练集的每一项(AuthorId,ConfirmedPaperIds,DeletedPaperIds)
for item in data:
authorId = item["AuthorId"] #取AuthorId列的值
# 构造训练正样本
for paperId in item["ConfirmedPaperIds"].split(" "):
#调用AuthorIdPaperId类的构造函数
authorIdPaperId = AuthorIdPaperId(authorId, paperId)
authorIdPaperId.label = 1 #正样本类标
authorIdPaperIds.append(authorIdPaperId) #存入列表
# 构造训练负样本,同上
for paperId in item["DeletedPaperIds"].split(" "):
authorIdPaperId = AuthorIdPaperId(authorId, paperId)
authorIdPaperId.label = 0 # 负样本类标
authorIdPaperIds.append(authorIdPaperId)
return authorIdPaperIds #返回列表集
def load_test_data(test_path):
#加载测试集Test.csv/验证集Valid.csv
data = util.read_dict_from_csv(test_path)
authorIdPaperIds = []
for item in data:
authorId = item["AuthorId"]
# 构造测试样本,将所有的PaperIds分隔构造类并全部附加进列表中
for paperId in item["PaperIds"].split(" "):
authorIdPaperId = AuthorIdPaperId(authorId, paperId)
authorIdPaperId.label = -1 # 待预测,暂时赋值为1...
authorIdPaperIds.append(authorIdPaperId)
return authorIdPaperIds
5.5 coauthor.py
该文件是生成$\textrm{4.5 coauthor.json}$文件的源代码,流程解释写在了注释中,
需要注意的是该代码的原文件是$\textrm{python2}$的代码,要修改成$\textrm{python3}$可以执行的代码,需调整以下几个部分:
- 所有的 $\textrm{print xxx}$ 改成$\textrm{print(xxx)}$
- $\textrm{python2}$中的$\textrm{reload(sys)}$转$\textrm{python3}$的$\textrm{reload(sys)}$
- 代码中$\textrm{data = util.read_dict_from_csv(paper_author_path)}$使用的是$\textrm{util.py}$中定义的方法,该方法使用$\textrm{csv}$库的函数进行$\textrm{csv}$文件的阅读,但是在该函数中,使用的是$\textrm{with open(in_file) as csvfile}$的语法,导致默认阅读的编码方式是$\textrm{GBK}$,因为需要修改成$\textrm{with open(in_file,"r",encoding="utf-8 ") as csvfile}$的形式
下面这份代码是已经修改后的版本,可以使用$\textrm{Python3}$直接执行。需要注意的是由于$\textrm{PaperAuthor.csv}$的行数高达$\textrm{104w}$,因此执行时间可能需要几十分钟到数个小时。
# KDD_Benchmark\model_trainer\coauthor.py
#!/usr/bin/env python
#encoding: utf-8
import os
'''
python在安装时,默认的编码是ascii
当程序中出现非ascii编码时,python的处理常常会报错UnicodeDecodeError:
'ascii' codec can't decode byte 0x?? in position 1:ordinal not in range(128),
python没办法处理非ascii编码的,此时需要自己设置python的默认编码,
一般设置为utf8的编码格式,在程序中加入以下代码:即可将编码设置为utf-8
在其他文件中也是同样的作用,便不做多余的解释
'''
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
sys.path.append("../")
import util
import json
from collections import Counter
import config
# 根据PaperAuthor.csv,获取每个作者的top k个共作者
def get_top_k_coauthors(paper_author_path, k, to_file):
#首先读取csv文件到data中
data = util.read_dict_from_csv(paper_author_path)
#创建字典1,将相同论文的作者进行合并,
#其元素类型为: key = PaperId,val = [AuthorId1,AuthodId2...]
dict_paperId_to_authors = {}
for item in data: #对于csv文件中的每一行,即每一项
paperId = int(item["PaperId"]) #读取PaperId列
authorId = int(item["AuthorId"]) #读取AuthorId列
#先检索字典中是否存在键,没有则需创建空列表
if paperId not in dict_paperId_to_authors:
dict_paperId_to_authors[paperId] = []
#然后将值append到列表中
dict_paperId_to_authors[paperId].append(authorId)
#然后再创建字典2,统计合作作者的次数
#其元素类型为: key = authorId,value = {coauthorId1:c1,coauthorId2:c2...}
#其中value是Counter()计数器类型
dict_author_to_coauthor = {}
#枚举字典1中的每一项,对于某篇论文
for paperId in dict_paperId_to_authors:
authors = dict_paperId_to_authors[paperId] #获取该论文的所有作者
n = len(authors) #记录作者数
for i in range(n): #枚举所有的组合类型
for j in range(i+1, n):
#尚不在字典中的键,则先初始化一个Counter计数器
if authors[i] not in dict_author_to_coauthor:
dict_author_to_coauthor[authors[i]] = Counter()
if authors[j] not in dict_author_to_coauthor:
dict_author_to_coauthor[authors[j]] = Counter()
#然后将相应的计数器+1
dict_author_to_coauthor[authors[i]][authors[j]] += 1
dict_author_to_coauthor[authors[j]][authors[i]] += 1
print("取 top k...")
# 取 top k
# authorid --> { author1: 100, author2: 45}
res = {}#字典3,结果存储字典,key = authorId, value = dict{coauthorId1:c1,coauthorId2:c2...}
#枚举字典2的每一项
for authorId in dict_author_to_coauthor:
res[authorId] = {} #先初始化键值字典
#调用Counter的most_common()函数,只将最频繁出现的k个值写入字典中
for coauthorId, freq in dict_author_to_coauthor[authorId].most_common(k):
res[authorId][coauthorId] = freq
print("dump...")
#将结果编码成json文件,写入指定路径
json.dump(res, open(to_file, "w",, encoding="utf-8"))
if __name__ == '__main__':
k = 10 #可以在此处根据需要修改k的值
get_top_k_coauthors(
os.path.join(config.DATASET_PATH, "PaperAuthor.csv"),#源文件路径
k,
os.path.join(config.DATA_PATH, "coauthor.json")) #生成文件路径
5.6 stringDistance.py
该文件是生成$\textrm{4.6 paperIdAuthorId_to_name_and_affiliation1.json}$文件的源代码,与上文相同,该代码的原文件$\textrm{python2}$代码,要修改成$\textrm{python3}$可以执行的代码,要做和上文相同的调整。
下面这份代码是已经修改后的版本,可以使用$\textrm{Python3}$直接执行。同样要注意的是因$\textrm{PaperAuthor.csv}$的行数高达$\textrm{104w}$,因此执行时间可能需要十分钟左右。
#!/usr/bin/env python
#encoding: utf-8
import os
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
sys.path.append("../")
import config
import json
import util
# PaperAuthor.csv文件包含噪音的,同一个(authorid,paperid)可能出现多次,
# 则可以把同一个(authorid,paperid)对的多个name和多个affiliation合并起来。例如
# aid,pid,name1,aff1
# aid,pid,name2,aff2
# aid,pid,name3,aff3
# 得到aid,pid,name1##name2##name3,aff1##aff2##aff3,“##”为分隔符
def load_paperIdAuthorId_to_name_and_affiliation(PaperAuthor_PATH, to_file):
d = {} #字典1
#KDD_Benchmark\data\dataset\PaperAuthor.csv, with format:
'''
PaperId-> int->论文编号
AuthorId-> int->作者编号
Name->string->作者名称
Affiliation->string->隶属单位
'''
data = util.read_dict_from_csv(PaperAuthor_PATH)#读取PaperAuthor.csv文件
for item in data: #枚举每一条记录
PaperId = item["PaperId"]
AuthorId = item["AuthorId"]
Name = item["Name"]
Affiliation = item["Affiliation"]
#提取各个参数
key = "%s|%s" % (PaperId, AuthorId) #构造字典key值
if key not in d: #对于尚未在字典中的,初始化value为{Name:[],Affiliation:[]}
d[key] = {}
d[key]["Name"] = []
d[key]["Affiliation"] = []
if Name != "": #空项不并入字典1中,下同
d[key]["Name"].append(Name)
if Affiliation != "":
d[key]["Affiliation"].append(Affiliation)
t = {} #字典2
for key in d: #对于字典1中的每一项
name = "##".join(d[key]["Name"]) #将val列表中的每一项用##连接为字符串
affiliation = "##".join(d[key]["Affiliation"])
#重构字典
t[key] = {}
t[key]["name"] = name
t[key]["affiliation"] = affiliation
#通过dump函数写入paperIdAuthorId_to_name_and_affiliation.json文件当中
json.dump(t, open(to_file, "w", encoding="utf-8"))
if __name__ == '__main__':
load_paperIdAuthorId_to_name_and_affiliation(config.PAPERAUTHOR_FILE, config.DATASET_PATH + "/paperIdAuthorId_to_name_and_affiliation.json")
5.7 evalution.py
#!/usr/bin/env python
#encoding: utf-8
import os
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
sys.path.append("../")
import util
import config
from confusion_matrix import Alphabet, ConfusionMatrix
# 对模型的预测结果,重新进行整理,得到想要的格式的预测结果
# 即通过特征文件记录的Aid与Pid和result文件中的预测结果,合并出一个.predict文件
# 使得文件格式与标准答案文件一致
def get_prediction(test_feature_path, test_result_path, to_file):
# 去除首尾空白符之后,分行存储两个文件的每一行
feature_list = [line.strip() for line in open(test_feature_path)]
predict_list = [line.strip() for line in open(test_result_path)]
dict_authorId_to_predict = {}
for feature, predict in zip(feature_list, predict_list):
#通过#分隔符找到pid和aid
paperId, authorId = feature.split(" # ")[-1].split(" ")
paperId = int(paperId)
authorId = int(authorId)
#初始化
if authorId not in dict_authorId_to_predict:
dict_authorId_to_predict[authorId] = {}
dict_authorId_to_predict[authorId]["ConfirmedPaperIds"] = []
dict_authorId_to_predict[authorId]["DeletedPaperIds"] = []
#根据便签归类结果
if predict == "1":
dict_authorId_to_predict[authorId]["ConfirmedPaperIds"].append(paperId)
if predict == "0":
dict_authorId_to_predict[authorId]["DeletedPaperIds"].append(paperId)
# to csv, 按照字典的key值进行排序
items = sorted(list(dict_authorId_to_predict.items()), key=lambda x: x[0])
data = []
for item in items:
AuthorId = item[0]
# 以空格为分隔符进行字符串的拼接
ConfirmedPaperIds = " ".join(map(str, item[1]["ConfirmedPaperIds"]))
DeletedPaperIds = " ".join(map(str, item[1]["DeletedPaperIds"]))
# 转换为字典
data.append({"AuthorId": AuthorId, "ConfirmedPaperIds": ConfirmedPaperIds, "DeletedPaperIds": DeletedPaperIds})
# 将字典写为csv文件
util.write_dict_to_csv(["AuthorId", "ConfirmedPaperIds", "DeletedPaperIds"], data, to_file)
# 评估(预测 vs 标准答案)
def Evalution(gold_file_path, pred_file_path):
gold_authorIdPaperId_to_label = {} #标准答案存储字典
pred_authorIdPaperId_to_label = {} #预测结果存储字典
#上述两字典的数据类型为 {key->tuple:val->int}
#其中tuple = (AuthorId, paperId), int = 正样本1/负样本0
#读取标准答案文件到gold_data中,type(gold_data)为list[dict1,dict2...]
gold_data = util.read_dict_from_csv(gold_file_path)
#枚举每一项
for item in gold_data:
AuthorId = item["AuthorId"]
# 正样本
for paperId in item["ConfirmedPaperIds"].split(" "):
gold_authorIdPaperId_to_label[(AuthorId, paperId)] = "1"
# 负样本
for paperId in item["DeletedPaperIds"].split(" "):
gold_authorIdPaperId_to_label[(AuthorId, paperId)] = "0"
#读取预测结果文件到pred_data中,流程同上
pred_data = util.read_dict_from_csv(pred_file_path)
for item in pred_data:
AuthorId = item["AuthorId"]
# 正样本
for paperId in item["ConfirmedPaperIds"].split(" "):
pred_authorIdPaperId_to_label[(AuthorId, paperId)] = "1"
# 负样本
for paperId in item["DeletedPaperIds"].split(" "):
pred_authorIdPaperId_to_label[(AuthorId, paperId)] = "0"
# evaluation
alphabet = Alphabet() #创建一个Alphabet类,定义于confusion_matrix.py文件当中
alphabet.add("0") # 添加label:0, {0:0}
alphabet.add("1") # 添加label:1, {1:1}
# 以alphabet为参数创建一个混淆矩阵
cm = ConfusionMatrix(alphabet)
# 统计每一条记录的预测结果和标准答案,加入混淆矩阵
for AuthorId, paperId in gold_authorIdPaperId_to_label:
gold = gold_authorIdPaperId_to_label[(AuthorId, paperId)]
pred = pred_authorIdPaperId_to_label[(AuthorId, paperId)]
cm.add(pred, gold)
return cm
if __name__ == '__main__':
gold_file_path = sys.argv[1] #从命令行参数获取标答文件路径
pred_file_path = sys.argv[2] #从命令行参数获取预测结果路径
#ConfusionMatrix类位于 confusion_matrix.py文件当中
#调用Evalution函数,返回一个ConfusionMatrix类实例
cm = Evalution(gold_file_path, pred_file_path)
#调用ConfusionMatrix类的get_accuracy()函数
acc = cm.get_accuracy()
# 打印评估结果
print("")
print("##" * 20)
print(" 评估结果, 以Accuracy为准")
print("##" * 20)
print("")
cm.print_out() #调用ConfusionMatrix类的print_out()函数
5.8 feature.py
#coding:utf-8
# 特征类
class Feature:
def __init__(self,name, dimension, feat_dict):
'''
特征类的构造函数
传入的参数包括特征名称,特征维度以及特征字典
对于特征字典,调用下文的featDict2String函数
将形如{k1:v1,k2:v2,k3:v3...kn:vn}的字典首先以key进行排序
然后转换为 "k1:v1 k2:v2 k3:v3..."的字符串形式
'''
self.name = name #特征名称
self.dimension = dimension #维度
self.feat_string = self.featDict2String(feat_dict) #特征: "3:1 7:1 10:0.5"
def featDict2String(self, feat_dict):
#按键值排序
list = [str(key)+":"+str(feat_dict[key]) for key in sorted(feat_dict.keys())]
return " ".join(list)
5.9 feature_functions.py
$\textrm{5.8 KDD_Benchmark\\model_trainer\\feature_functions.py}$
特征抽取函数:实现了一些特征的计算函数,包括
在$\textrm{5.3}$节中介绍了$\textrm{coauthor.py}$的流程—即如何生成$\textrm{coauthor.json}$文件,在$\textrm{4.5}$节中介绍了$\textrm{coauthor.json}$的文件格式以及使用方法,现在将通过该文件实现共作者的相似度特征计算。而在$\textrm{5.4}$节中介绍了$\textrm{paperIdAuthorId_to_name_and_affiliation.json}$的生成原理,$\textrm{4.6}$节中介绍了该文件格式以及使用方法,同时他也是字符串特征函数的依赖文件。对于每个特征函数的解释均写在了注释之中,可以通过阅读下方代码理解原理。
#!/usr/bin/env python
#encoding: utf-8
# import sys
# import importlib
# importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
import util
import numpy as np
# coauthor信息
# 很多论文都有多个作者,根据paperauthor统计每一个作者的top 10(当然可以是top 20或者其他top K)的coauthor,
# 对于一个作者论文对(aid,pid),计算ID为pid的论文的作者有没有出现ID为aid的作者的top 10 coauthor中,
# (1). 可以简单计算top 10 coauthor出现的个数,
# (2). 还可以算一个得分,每个出现pid论文的top 10 coauthor可以根据他们跟aid作者的合作次数算一个分数,然后累加,
# 我简单地把coauthor和当前aid作者和合作次数作为这个coauthor出现的得分。
'''
对于四个特征函数输入参数解释:
AuthorIdPaperId:
{
参数类型: AuthorIdPaperId类 (defined in authorIdPaperId.py)
可以理解为唯一的input变量,其他参数在不更换源文件的情况下在每次调用时均不会改变
该类包含(作者id,论文id,label)三个类成员
在该文件中通过提取作者id和论文id来生成相应的特征
}
dict_coauthor
{
参数类型: 字典 generated from coauthor.json
key类型为作者id
val类型仍为字典,其格式为{a1:count1,a2:count2...ak:countk}
}
dict_paperIdAuthorId_to_name_aff
{
参数类型: 字典 generated from dictionary from paperIdAuthorId_to_name_and_affiliation.json
key类型为string,format为"PaperId|AuthorId"的复合形式
value类型为字典,其格式为{"affiliation":"a1|a2|...|an","name":"n1|n2|...|nm"}
}
PaperAuthor
{
参数类型: DataFrame, read from PaperAuthor.csv by pandas
DateFrame包括的列有:
PaperId int 论文编号
AuthorId int 论文编号
Name string 作者名称
Affiliation string 隶属单位
}
Author
{
参数类型: DataFrame, read from Author.csv by pandas
DateFrame包括的列有:
Id int 作者编号
Name string 作者名称
Affiliation string 隶属单位
}
'''
# 1. 简单计算top 10 coauthor出现的个数
def coauthor_1(AuthorIdPaperId, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author):
# 从类成员中提取作者id与论文id
authorId = AuthorIdPaperId.authorId
paperId = AuthorIdPaperId.paperId
'''
用xxx表示上一行的语句,以此来体现嵌套关系
PaperAuthor["PaperId"] == int(paperId) 在某个item.PaperId = AuthorIdPaperId.paperId会返回true
而PaperAuthor[xxx]则是枚举所有item,只保留方框内值为true的项
xxx["AuthorId"] 则是取这些保留的item的AuthorId的值
list(xxx.values)则是将这些值取出以列表的转换为列表
list(map(str,xxx))是将所有值从int转换为字符串类型,再重新将map对象变回列表
所以整个语句的含义就是返回一个列表,列表中包含了所有PaperId = AuthorIdPaperId.paperId的AuthorId,且类型为string
'''
curr_coauthors = list(map(str, list(PaperAuthor[PaperAuthor["PaperId"] == int(paperId)]["AuthorId"].values)))
# 获取输入作者的最频繁的k个合作作者,以[a1,a2,a3...]的形式返回
top_coauthors = list(dict_coauthor[authorId].keys())
# 将两个列表转换为集合,做交集运算,计算交集的元素个数
nums = len(set(curr_coauthors) & set(top_coauthors))
'''
简单分析nums的意义:实际输入的参数仅有一个Pid和一个Aid, 伴随输入的参数还有多个字典
通过字典先找出Pid的所有作者S1
然后又找出Aid的高频合作作者S2
然后取交集
也就是说,我们分析一个Pid和一个Aid之间的特征值是通过该篇论文的所有作者有多少个和给定的作者频繁合作
蕴含的意义就是,对于作者a,如果他经常和作者b,c,d,e...k个人合作
那么现在已知某篇论文已经被b,c,d,e...k写过了,那么很可能a也写了该论文
nums便是上文的k
最后返回的结果是一个Feature特征类(in feature.py)
类的构造方法调用了util.py中的get_feature_by_list的函数,有关该函数的说明写在了util.py当中
这里直接说明最后特征类的结果
class Feature:
self.name = ""
self.dimension = 1
self.feat_string = "1:nums"
'''
return util.get_feature_by_list([nums])
# 2. 还可以算一个得分,每个出现pid论文的top 10 coauthor可以根据他们跟aid作者的合作次数算一个分数,然后累加,
def coauthor_2(AuthorIdPaperId, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author):
# 从类成员中提取作者id与论文id
authorId = AuthorIdPaperId.authorId
paperId = AuthorIdPaperId.paperId
#该语句的解释同coauthor_1函数
curr_coauthors = list(map(str, list(PaperAuthor[PaperAuthor["PaperId"] == int(paperId)]["AuthorId"].values)))
# 与coauthor1函数不同的是,除了作者的合作作者之外,还取值他们的合作次数
# top_coauthors的格式形如 {"name1": times1, "name2":times2...}
top_coauthors = dict_coauthor[authorId]
# 同样找两个对象之间的交集,与coauthor1不同的是,每个合作的作者多了一个权重:合作此时
score = 0
for curr_coauthor in curr_coauthors:
if curr_coauthor in top_coauthors:
score += top_coauthors[curr_coauthor]
'''
同样分析一下score的意义
在coauthor_1函数中,曾举过例子:如果该作者与k个人合作过,而某篇论文恰好也被这k个人写过,
那么该作者很有可能写过该论文,score在nums的基础上更精细化的处理了,考虑A与B,C均合作过
其中A与B合作了100次,A只与C合作了1次,现在有两篇论文X,Y
已知X被B写了,Y被C写了,那么显然A写X的概率远大于A写Y
但是在coauthor_1函数中,(A,X)与(A,Y)却有相同的nums值,显然不太合理
而在coauthor_2函数中 (A,X)的score = 100, (A,Y)的score = 1,区分得以体现
返回的特征类
class Feature:
self.name = ""
self.dimension = 1
self.feat_string = "1:score"
'''
return util.get_feature_by_list([score])
''' String Distance Feature'''
# 1. name-a 与name1##name2##name3的距离,同理affliction-a 和 aff1##aff2##aff3的距离
def stringDistance_1(AuthorIdPaperId, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author):
authorId = AuthorIdPaperId.authorId
paperId = AuthorIdPaperId.paperId
#首先构造出dict_paperIdAuthorId_to_name_aff的key类型: AuthorId|PaperId
key = "%s|%s" % (paperId, authorId)
#然后通过查询字典获取其全部的name属性与affiliation属性
#name = "name1##name2##name3##..."
#aff = "aff1##aff2##aff3##..."
name = str(dict_paperIdAuthorId_to_name_aff[key]["name"])
aff = str(dict_paperIdAuthorId_to_name_aff[key]["affiliation"])
'''
Author包含Id(作者编号),Name(作者名称),Affiliation(隶属单位)三个列
Author[Author["Id"] == int(authorId)].values是所有Id为authorId的行,格式为[["Id Name Aff"]]
list(xxx) 将其转换为 [array([Id,Name,Aff])]
T = xxx[0]则为[Id,Name,Aff]
因此 str(T[1])即为Name属性,str(T[2])即为Affiliation属性
"nan"是在属性为空时的返回值,因为文件描述中有说到,属性值可能为空,因此手动将nan转换为空字符,避免干扰
'''
T = list(Author[Author["Id"] == int(authorId)].values)[0]
a_name = str(T[1])
a_aff = str(T[2])
if a_name == "nan":
a_name = ""
if a_aff == "nan":
a_aff = ""
feat_list = []
#需要注意的是,此时name并未被分割,因此计算的是形如 a_name与 name1##name2##name3##...之间的距离
# 计算 a_name 与 name 的距离
feat_list.append(len(longest_common_subsequence(a_name, name)))
feat_list.append(len(longest_common_substring(a_name, name)))
feat_list.append(Levenshtein_distance(a_name, name))
# 计算 a_aff 与 aff 的距离
feat_list.append(len(longest_common_subsequence(a_aff, aff)))
feat_list.append(len(longest_common_substring(a_aff, aff)))
feat_list.append(Levenshtein_distance(a_aff, aff))
'''
feat_list = [d1,d2,d3,d4,d5,d6]
于是构造的特征类格式为
class Feature:
self.name = ""
self.dimension = 6
self.feat_string = "1:d1 2:d2 3:d3 4:d4 5:d5 6:d6"
'''
return util.get_feature_by_list(feat_list)
'''
整体分析两个字符串特征函数的意义
对于输入的Pid与Aid,查询(Pid,Aid)在PaperAuthor.csv出现的全部name与aff信息
然后又查询Author.csv中Aid对应的name与aff信息
也就是说对于一个论文作者对,分别查询(论文,作者)的姓名与隶属单位
然后又查询作者本身的姓名与隶属单位,对比二者,如果评估的数值结果较大
那么可以认为作者写了该论文。
但是该过程存在诸多问题: PaperAuthor.csv中记录的是某作者写了某论文
也就是说(Pid,Aid)不一定出现在了该文件中,查询字典的时候可能报错
其次,如果(Pid,Aid)出现在了该文件中,那就说明作者写了论文,但在介绍文件的时候说过
该文件包含噪声,出现并不意味着绝对写过,论文-作者对本身可能是错误数据
因此字符串特征函数的用意应该是消除噪音,试想一下
假设(P1,A1)出现在了PaperAuthor.csv当中3次
但是我们需要判定(P1,A1)本身是否是正确的(例如将A2抄成了A1)
那么我们对比A1在Author.csv中的姓名和单位
如果二者相同或者在语义上很接近,那么可以判定这是一条正确的记录
也就是说,这两个函数不适合作为特征函数传入训练文件当中
而是更适合作为清洗数据的预处理函数
'''
# 2. name-a分别与name1,name2,name3的距离,然后取平均,同理affliction-a和,aff1,aff2,aff3的平均距离
def stringDistance_2(AuthorIdPaperId, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author):
authorId = AuthorIdPaperId.authorId
paperId = AuthorIdPaperId.paperId
key = "%s|%s" % (paperId, authorId)
name = str(dict_paperIdAuthorId_to_name_aff[key]["name"])
aff = str(dict_paperIdAuthorId_to_name_aff[key]["affiliation"])
T = list(Author[Author["Id"] == int(authorId)].values)[0]
a_name = str(T[1])
a_aff = str(T[2])
if a_name == "nan":
a_name = ""
if a_aff == "nan":
a_aff = ""
feat_list = []
#以上均与stringDistance_1函数的内容相同
#不同的是,将 name1##name2##...进行分割了
# 计算 a_name 与 name 的距离
lcs_distance = []
lss_distance = []
lev_distance = []
for _name in name.split("##"):
lcs_distance.append(len(longest_common_subsequence(a_name, _name)))
lss_distance.append(len(longest_common_substring(a_name, _name)))
lev_distance.append(Levenshtein_distance(a_name, _name))
#用分割后的多个值的平均值取代整体计算结果
feat_list += [np.mean(lcs_distance), np.mean(lss_distance), np.mean(lev_distance)]
# 计算 a_aff 与 aff 的距离
lcs_distance = []
lss_distance = []
lev_distance = []
for _aff in aff.split("##"):
lcs_distance.append(len(longest_common_subsequence(a_aff, _aff)))
lss_distance.append(len(longest_common_substring(a_aff, _aff)))
lev_distance.append(Levenshtein_distance(a_aff, _aff))
feat_list += [np.mean(lcs_distance), np.mean(lss_distance), np.mean(lev_distance)]
'''
feat_list = [d1,d2,d3,d4,d5,d6]
class Feature:
self.name = ""
self.dimension = 6
self.feat_string = "1:d1 2:d2 3:d3 4:d4 5:d5 6:d6"
'''
return util.get_feature_by_list(feat_list)
''' 一些距离计算方法 '''
# 最长公共子序列(LCS), 获取是a, b的最长公共子序列, 可参考下方链接
# https://leetcode-cn.com/problems/longest-common-subsequence/solution/zui-chang-gong-gong-zi-xu-lie-by-leetcod-y7u0/
def longest_common_subsequence(a, b):
lengths = [[0 for j in range(len(b) + 1)] for i in range(len(a) + 1)]
# row 0 and column 0 are initialized to 0 already
for i, x in enumerate(a):
for j, y in enumerate(b):
if x == y:
lengths[i + 1][j + 1] = lengths[i][j] + 1
else:
lengths[i + 1][j + 1] = max(lengths[i + 1][j], lengths[i][j + 1])
# read the substring out from the matrix
result = ""
x, y = len(a), len(b)
while x != 0 and y != 0:
if lengths[x][y] == lengths[x - 1][y]:
x -= 1
elif lengths[x][y] == lengths[x][y - 1]:
y -= 1
else:
assert a[x - 1] == b[y - 1]
result = a[x - 1] + result
x -= 1
y -= 1
return result
# 最长公共子串(LSS),对于该问题的详解可参考下方链接
# https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray/solution/zui-chang-zhong-fu-zi-shu-zu-by-leetcode-solution/
def longest_common_substring(a, b):
m = [[0] * (1 + len(b)) for i in range(1 + len(a))]
longest, x_longest = 0, 0
for x in range(1, 1 + len(a)):
for y in range(1, 1 + len(b)):
if a[x - 1] == b[y - 1]:
m[x][y] = m[x - 1][y - 1] + 1
if m[x][y] > longest:
longest = m[x][y]
x_longest = x
else:
m[x][y] = 0
return a[x_longest - longest: x_longest]
# 编辑距离,对于该问题的详解可参考下方
# https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
def Levenshtein_distance(input_x, input_y):
xlen = len(input_x) + 1 # 此处需要多开辟一个元素存储最后一轮的计算结果
ylen = len(input_y) + 1
dp = np.zeros(shape=(xlen, ylen), dtype=int)
for i in range(0, xlen):
dp[i][0] = i
for j in range(0, ylen):
dp[0][j] = j
for i in range(1, xlen):
for j in range(1, ylen):
if input_x[i - 1] == input_y[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = 1 + min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1])
return dp[xlen - 1][ylen - 1]
if __name__ == '__main__':
print(Levenshtein_distance("abc", "ab"))
5.10 example.py
实例类
在上文中介绍了关于特征类的构造和特征函数的设计,接下来需要将计算出来的特征值存储为文件的形式便于调用,以免反复计算。而下文的$\textrm{Example}$就是为了生成文件设计的,每一个$\textrm{Example}$类就是生成文件中的一行,类的成员包含$\textrm{content}$和$\textrm{comment}$,分别表示特征内容与描述对象。
# encoding: utf-8
# 将特征文件的每一行表示为一个类
class Example:
def __init__(self, target, feature, comment=""):
# target表示样本类型 feature.feat_string表示特征值
self.content = str(target) + " " + feature.feat_string
self.comment = comment
5.11 make_fearue_file.py
在$\textrm{5.9 feature_functions.py}$中介绍了对于单个$\textrm{AuthorIdPaperId}$类的特征值计算方法,而本节代码则是一次传入多个$\textrm{AuthorIdPaperId}$类,对于每个类调用指定的特征函数生成,然后通过$\textrm{util.py}$文件中的函数进行合并然后写入文件。由于本节代码调用$\textrm{util.py}$的函数较多,可以结合$\textrm{5.12 util.py}$一起阅读。
#encoding: utf-8
# import pyprind
import util
from example import Example
'''
Make_feature_file函数:生成特征文件
输入参数解释:
authorIdPaperIds:
{
参数类型: 列表,列表中的每个元素类型为AuthorIdPaperId类 (defined in authorIdPaperId.py)
该类包含(作者id,论文id,label)三个类成员
}
dict_coauthor
{
参数类型: 字典 generated from coauthor.json
key类型为作者id
val类型仍为字典,其格式为{a1:count1,a2:count2...ak:countk}
}
dict_paperIdAuthorId_to_name_aff
{
参数类型: 字典 generated from dictionary from paperIdAuthorId_to_name_and_affiliation.json
key类型为string,format为"PaperId|AuthorId"的复合形式
value类型为字典,其格式为{"affiliation":"a1|a2|...|an","name":"n1|n2|...|nm"}
}
PaperAuthor
{
参数类型: DataFrame, read from PaperAuthor.csv by pandas
DateFrame包括的列有:
PaperId int 论文编号
AuthorId int 论文编号
Name string 作者名称
Affiliation string 隶属单位
}
Author
{
参数类型: DataFrame, read from Author.csv by pandas
DateFrame包括的列有:
Id int 作者编号
Name string 作者名称
Affiliation string 隶属单位
}
feature_function_list: 列表,包含了所有特征函数的函数名称,形如[coauthor_1,coauthor_2,...]
to_file:生成文件路径和文件名
'''
def Make_feature_file(authorIdPaperIds, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author, feature_function_list, to_file):
example_list = []
dimension = 0
# process_bar = pyprind.ProgPercent(len(authorIdPaperIds))
# 枚举列表中每一个AuthorIdPaperId类实例,转换成一个example实例
for authorIdPaperId in authorIdPaperIds:
# process_bar.update()
# 调用所有的特征函数生成若干个Feature类存放在features中
# feature = [Feature1,Feature2,Feature3...]
features = [feature_function(authorIdPaperId, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author) for feature_function in feature_function_list]
# 合并特征,关于mergeFeatures的解释可以参见util.py中的注释
# 得到的feature的name为空,dimension为features中的dimension之和
# feat_string为features中feat_string重排key值之后拼接得到
feature = util.mergeFeatures(features)
dimension = feature.dimension
#特征target
target = authorIdPaperId.label
if target is None:
target = "-1" #-1表示尚未分类
#然后构造一个example类
example = Example(target, feature)
# example.comment = json.dumps({"paperId": authorIdPaperId.paperId, "authorId": authorIdPaperId.authorId})
# comment则用paperId和authorId拼接得到
example.comment = "%s %s" % (authorIdPaperId.paperId, authorIdPaperId.authorId)
example_list.append(example)
# 调用util.py中的write_example_list_to_file函数将example类写入特征文件
# 函数的注释可在util.py中查看
# 每一行的格式为 tar key1:val1 key2:val2 ... key_n:val_n # paperId authorId
util.write_example_list_to_file(example_list, to_file)
# 调用util.py中的write_example_list_to_arff_file函数将example类写入arff文件
# 函数的注释可在util.py中查看
# 此外关于arff文件的介绍也可以在util.py中定义该函数的上方找到
util.write_example_list_to_arff_file(example_list, dimension, to_file+".arff")
5.12 util.py
该文件中包含了若干个辅助用的函数,包括:
- $\textrm{write_dict_to_csv:}$将字典写入$\textrm{csv}$文件
- $\textrm{read_dict_from_csv:}$将$\textrm{csv}$文件读取到字典中
- $\textrm{get_feature_by_feat:}$根据单个特征值构造特征类
- $\textrm{get_feature_by_list:}$用列表构造特征字典,进而转换为特征类
- $\textrm{get_feature_by_feat_list:}$根据多个特征值构造特征类
- $\textrm{mergeFeatures:}$将多个特征类对象合并成一个
- $\textrm{write_example_list_to_file:}$将$\textrm{example}$类写入特征文件
- $\textrm{write_example_list_to_arff_file:}$将$\textrm{example}$类写入$\textrm{arff}$文件
有关各个函数的流程、原理以及$\textrm{arff}$文件的解释均写在了下文的注释当中。
#!/usr/bin/env python
#encoding: utf-8
import csv
import os
import sys
from feature import Feature
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
'''
将字典写入csv文件函数
fieldnames:列名,格式形如 ['first_name', 'last_name']
contents:字典本体,格式形如[{'first_name': 'Baked', 'last_name': 'Beans'}, {'first_name': 'Lovely', 'last_name': 'Spam'}]
to_file: 写入的路径与文件名
其中contents的格式为list,list中包含的对象为dict
即csv每一行的格式以字典的方式呈现,list[i]代表了第i行数据,list[i][field]代表了第i行的field域的值
'''
def write_dict_to_csv(fieldnames, contents, to_file):
with open(to_file, 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(contents)
'''
和上一个函数相反,该函数将csv文件还原成字典列表的格式
返回的参数类型形如[{'first_name': 'Baked', 'last_name': 'Beans'}, {'last_name': 'Lovely', 'last_name': 'Spam'}]
'''
def read_dict_from_csv(in_file):
if not os.path.exists(in_file):
return []
with open(in_file,"r",encoding="utf-8 ") as csvfile:
return list(csv.DictReader(csvfile))
'''
通过列表构造一个特征类
首先将列表转换为字典,转换方式为:
L[i] -> i+1: L[i]
即对于某个列表元素,以其{下标+1}为key,以元素本身为value
构造一个字典feat_dict
然后以""为name,len(list)为dimension,feat_dict为特征字典
构造一个Feature的类
'''
def get_feature_by_list(list):
feat_dict = {}
for index, item in enumerate(list):
if item != 0:
feat_dict[index+1] = item
return Feature("", len(list), feat_dict)
#根据单个特征值构造特征类
def get_feature_by_feat(dict, feat):
feat_dict = {}
if feat in dict:
feat_dict[dict[feat]] = 1
return Feature("", len(dict), feat_dict)
#根据多个特征值构造特征类
def get_feature_by_feat_list(dict, feat_list):
feat_dict = {}
for feat in feat_list:
if feat in dict:
feat_dict[dict[feat]] = 1
return Feature("", len(dict), feat_dict)
''' 合并 feature_list中的所有feature '''
# feature_list = [Feature1,Feature2,Feature3...]
# 存放了若干个Feature类对象,该函数用于将多个特征类对象进行合并
# 例如存在f1.feat_string = "1:5 2:10 3:15" f2.feat_string = "1:7 2:8 3:9"
# 那么合并之后得到 mf.feat_string = "1:5 2:10 3:15 4:7 5:8 6:9"
# 即将feat_string相加,但要重设index
def mergeFeatures(feature_list, name = ""):
# print "-"*80
# print "\n".join([feature_file.feat_string+feature_file.name for feature_file in feature_list])
dimension = 0
feat_string = ""
# 枚举每一个Feature对象
for feature in feature_list:
if dimension == 0:#第一个
feat_string = feature.feat_string #赋值特征
else:
if feature.feat_string != "":
#修改当前feature的index
temp = ""
for item in feature.feat_string.split(" "):
# 取原下标和特征值
index, value = item.split(":")
# 构造新索引
temp += " %d:%s" % (int(index)+dimension, value)
feat_string += temp # 合并特征值
dimension += feature.dimension # 加上维度值
# 最后构造一个特征类,将合并的特征值去除首尾空格后(strip)赋值
merged_feature = Feature(name, dimension, {})
merged_feature.feat_string = feat_string.strip()
return merged_feature
# 将example类写入特征文件中
# example_list为存放若干个example类的列表, to_file为写入路径和文件名
def write_example_list_to_file(example_list, to_file):
with open(to_file, "w") as fout:
fout.write("\n".join([example.content + " # " + example.comment for example in example_list]))
# 每一行的格式为 tar key1:val1 key2:val2 ... key_n:val_n # paperId authorId
'''
arff:Attribute-Relation File Format。
arff是一个ASCII文本文件,记录了一些共享属性的实例。
此类格式的文件主要由两个部分构成,头部定义和数据区。
头部定义包含了关系名称(relation name),一些属性(attributes)和对应的类型,如:
'''
# 将example类写入arff文件
def write_example_list_to_arff_file(example_list, dimension, to_file):
with open(to_file, "w") as fout:
out_lines = []
out_lines.append("@relation kdd") #arff关系名称
out_lines.append("")
for i in range(dimension):
# arff属性名称 属性类型为numeric数值类型
out_lines.append("@attribute attribution%d numeric" % (i+1))
# 取值类型限定为{0,1}
out_lines.append("@attribute class {0, 1}")
out_lines.append("")
out_lines.append("@data") # 数据区域
for example in example_list:
feature_list = [0.0] * dimension
s = example.content.split(" ")
#s = [tar,key1:val1,key2:val2,...,key_n:val_n]
target = s[0]
for item in s[1:]:
if item == "": #跳过空项
continue
k, v = int(item.split(":")[0]) - 1, float(item.split(":")[1])
feature_list[k] = v
# 即将Feature全部特征值取出按下标顺序记录在feature中
feature = ",".join(map(str, feature_list))
# 用逗号作为分隔符拼接起来,最后并上target作为类标
out_lines.append("%s,%s" % (feature, target))
fout.write("\n".join(out_lines))
if __name__ == '__main__':
s = "0 ".split(" ")
print(s)
5.13 test.py
该文件为测试文件,不参与最终主函数的执行,是为了测试特征文件是否可以被$\textrm{load_svmlight_file}$正确的读取并建立模型。
#!/usr/bin/env python
#encoding: utf-8
import json
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf-8')
sys.path.append("../")
import joblib
#from sklearn.externals.joblib import Memory
from sklearn.datasets import load_svmlight_file
from sklearn import svm
if __name__ == '__main__':
# load_svmlight_file加载特征文件
# 其中train_X为矩阵的格式
# (i,j) val表示第i行第j个特征值为val
# 而train_y为数组格式, train_y[i] = label表示第i行的标记值为label
train_X, train_y = load_svmlight_file("feature/train.feature")
test_X, test_y = load_svmlight_file("feature/test.feature")
# SVC:Support Vector Classification 支持向量机的分类器
clf = svm.SVC()
# fit(input,result) 将train_X作为输入数据,train_y作为标准输出进行训练
clf.fit(train_X, train_y)
# 再以test_X为输入,输出以上述模型为依据的预测结果
print(clf.predict(test_X))
5.14 classifier.py
该文件定义了一个$\textrm{10}$个类,包括一个抽象分类器类,$\textrm{8}$个派生出来的具体分类器,和一个调用这些分类器的主分类器类,对于抽象分类器,所有的成员函数均为空;对于主分类器,就是直接调用了具体分类器的成员函数,因此无需做多余解释。而对于$\textrm{8}$个具体分类器,他们的结构均完全一致,包括
- $\textrm{trainer:}$ 分类器名称,在主函数运行时用于打印提示字符
- $\textrm{clf:}$ 即$\textrm{classifier}$,分类器对象
- $\textrm{train_model:}$ 训练模型函数,流程包括
- 通过$\textrm{load_svmlight_file}$加载特征文件
- 调用$\textrm{sklearn}$的库进行模型训练
- $\textrm{test_model:}$ 测试模型函数
- 通过$\textrm{load_svmlight_file}$加载特征文件
- 调用$\textrm{sklearn}$的库进行模型预测
- 将预测结果写入结果文件中
这八个分类器包括:
- $\textrm{Classifier(skLearn_DecisionTree())}$: 决策树
- $\textrm{Classifier(skLearn_NaiveBayes())}$: 朴素贝叶斯
- $\textrm{Classifier(skLearn_svm())}$: 支持向量机
- $\textrm{Classifier(skLearn_lr())}$: 逻辑回归
- $\textrm{Classifier(skLearn_KNN())}$: $\textrm{k}$近邻算法$\textrm{(default k = 3)}$
- $\textrm{Classifier(sklearn_RandomForestClassifier())}$: 随机森林
- $\textrm{Classifier(skLearn_AdaBoostClassifier())}$: 集成学习
- $\textrm{Classifier(sklearn_VotingClassifier())}$: 投票分类
#coding:utf-8
import os, config
from sklearn.datasets import load_svmlight_file
from sklearn import svm, tree
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
#抽象类 所有的分类器都以此类为父类进行派生
class Strategy(object):
def train_model(self, train_file_path, model_path):
return None
def test_model(self, test_file_path, model_path, result_file_path):
return None
#主分类器 用于调用各个分类器
class Classifier(object):
def __init__(self, strategy):
self.strategy = strategy
def train_model(self, train_file_path, model_path):
self.strategy.train_model(train_file_path, model_path)
def test_model(self, test_file_path, model_path, result_file_path):
self.strategy.test_model(test_file_path, model_path, result_file_path)
''' skLearn '''
'''
每个模型都有两个类成员和两个成员函数
trainer : 分类器名称,在主函数运行时用于打印提示字符
clf : 即classifier,分类器对象
train_model : 训练模型函数
test_model: 测试模型函数
所有分类器的函数流程大同小异
在这里做统一解释:
train_model:
(1)通过load_svmlight_file加载特征文件
(2)调用sklearn的库进行模型训练
test_model:
(1)通过load_svmlight_file加载特征文件
(2)调用sklearn的库进行模型预测
(3)将预测结果写入结果文件当中
'''
#模型1: 决策树
class skLearn_DecisionTree(Strategy):
def __init__(self):
self.trainer = "skLearn decisionTree"
self.clf = tree.DecisionTreeClassifier()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型2: 朴素贝叶斯
class skLearn_NaiveBayes(Strategy):
def __init__(self):
self.trainer = "skLearn NaiveBayes"
self.clf = GaussianNB()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
train_X = train_X.toarray()
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
test_X = test_X.toarray()
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型3: 支持向量机
class skLearn_svm(Strategy):
def __init__(self):
self.trainer = "skLearn svm"
self.clf = svm.LinearSVC()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型4: 逻辑回归
class skLearn_lr(Strategy):
def __init__(self):
self.trainer = "skLearn LogisticRegression"
self.clf = LogisticRegression()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型5: k近邻算法(default k = 3)
class skLearn_KNN(Strategy):
def __init__(self):
self.trainer = "skLearn KNN"
self.clf = KNeighborsClassifier(n_neighbors=3)
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型6: 集成学习
class skLearn_AdaBoostClassifier(Strategy):
def __init__(self):
self.trainer = "skLearn AdaBoostClassifier"
self.clf = AdaBoostClassifier()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型7: 随机森林分类
class sklearn_RandomForestClassifier(Strategy):
def __init__(self):
self.trainer = "skLearn RandomForestClassifier"
self.clf = RandomForestClassifier()
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
#模型8: 投票分类(hard—少数服从多数)
class sklearn_VotingClassifier(Strategy):
def __init__(self):
self.trainer = "skLearn VotingClassifier"
clf1 = LogisticRegression()
clf2 = svm.LinearSVC()
clf3 = AdaBoostClassifier()
self.clf = VotingClassifier(estimators=[('lr', clf1), ('svm', clf2), ('ada', clf3)], voting='hard')
print("Using %s Classifier" % (self.trainer))
def train_model(self, train_file_path, model_path):
train_X, train_y = load_svmlight_file(train_file_path)
print("==> Train the model ...")
self.clf.fit(train_X, train_y)
def test_model(self, test_file_path, model_path, result_file_path):
print("==> Test the model ...")
test_X, test_y = load_svmlight_file(test_file_path)
pred_y = self.clf.predict(test_X)
# write prediction to file
with open(result_file_path, 'w') as fout:
fout.write("\n".join(map(str, map(int, pred_y))))
if __name__ == "__main__":
pass
5.15 confusion_matrix.py
该文件定义了混淆矩阵类和$\textrm{Alphabet}$类,用于打印最后的评估结果,文件虽然冗长,但是大部分函数没有在本次实验中被调用,且与算法本身无关,仅做了解即可。
# -*- coding: utf-8 -*-
"""A collection of data structures that are particularly
useful for developing and improving a classifier
"""
import numpy, json
# 混淆矩阵类
class ConfusionMatrix(object):
"""Confusion matrix for evaluating a classifier
For more information on confusion matrix en.wikipedia.org/wiki/Confusion_matrix"""
INIT_NUM_CLASSES = 100
def __init__(self, alphabet=None):
if alphabet is None:
self.alphabet = Alphabet()
self.matrix = numpy.zeros((self.INIT_NUM_CLASSES, self.INIT_NUM_CLASSES))
else:
self.alphabet = alphabet
num_classes = alphabet.size()
self.matrix = numpy.zeros((num_classes,num_classes))
def __iadd__(self, other):
self.matrix += other.matrix
return self
# 添加一次预测结果和标准答案
def add(self, prediction, true_answer):
"""Add one data point to the confusion matrix
If prediction is an integer, we assume that it's a legitimate index
on the confusion matrix.
If prediction is a string, then we will do the look up to
map to the integer index for the confusion matrix.
"""
if type(prediction) == int and type(true_answer) == int:
self.matrix[prediction, true_answer] += 1 #统计结果
else:
self.alphabet.add(prediction)
self.alphabet.add(true_answer)
prediction_index = self.alphabet.get_index(prediction)
true_answer_index = self.alphabet.get_index(true_answer)
self.matrix[prediction_index, true_answer_index] += 1 #统计结果
#XXX: this will fail if the prediction_index is greater than
# the initial capacity. I should grow the matrix if this crashes
# 批量添加统计结果
def add_list(self, predictions, true_answers):
for p, t in zip(predictions, true_answers):
self.add(p, t)
# 计算f1平均值
def compute_average_f1(self):
precision = numpy.zeros(self.alphabet.size())
recall = numpy.zeros(self.alphabet.size())
f1 = numpy.zeros(self.alphabet.size())
# computing precision, recall, and f1
for i in range(self.alphabet.size()):
precision[i] = self.matrix[i,i] / sum(self.matrix[i,:])
recall[i] = self.matrix[i,i] / sum(self.matrix[:,i])
if precision[i] + recall[i] != 0:
f1[i] = 2 * precision[i] * recall[i] / (precision[i] + recall[i])
else:
f1[i] = 0
return numpy.mean(f1)
def print_matrix(self):
num_classes = self.alphabet.size()
#header for the confusion matrix
header = [' '] + [self.alphabet.get_label(i) for i in range(num_classes)]
rows = []
#putting labels to the first column of rhw matrix
for i in range(num_classes):
row = [self.alphabet.get_label(i)] + [str(self.matrix[i,j]) for j in range(num_classes)]
rows.append(row)
print("row = predicted, column = truth")
print(matrix_to_string(rows, header))
def get_matrix(self):
num_classes = self.alphabet.size()
#header for the confusion matrix
header = [' '] + [self.alphabet.get_label(i) for i in range(num_classes)]
rows = []
#putting labels to the first column of rhw matrix
for i in range(num_classes):
row = [self.alphabet.get_label(i)] + [str(self.matrix[i,j]) for j in range(num_classes)]
rows.append(row)
return "row = predicted, column = truth\n" + matrix_to_string(rows, header)
def get_prf(self, class_name):
index = self.alphabet.get_index(class_name)
precision = self.matrix[index, index] / sum(self.matrix[index, :])
recall = self.matrix[index, index] / sum(self.matrix[:, index])
f1 = (2 * precision * recall) / (precision + recall)
return (precision, recall, f1)
def print_summary(self):
correct = 0
precision = numpy.zeros(self.alphabet.size())
recall = numpy.zeros(self.alphabet.size())
f1 = numpy.zeros(self.alphabet.size())
lines = []
# computing precision, recall, and f1
for i in range(self.alphabet.size()):
precision[i] = self.matrix[i,i] / sum(self.matrix[i,:])
recall[i] = self.matrix[i,i] / sum(self.matrix[:,i])
if precision[i] + recall[i] != 0:
f1[i] = 2 * precision[i] * recall[i] / (precision[i] + recall[i])
else:
f1[i] = 0
correct += self.matrix[i,i]
label = self.alphabet.get_label(i)
lines.append( '%s \tprecision %f \trecall %f\t F1 %f' %\
(label, precision[i], recall[i], f1[i]))
lines.append( '* Overall accuracy rate = %f' %(correct / sum(sum(self.matrix[:,:]))))
lines.append( '* Average precision %f \t recall %f\t F1 %f' %\
(numpy.mean(precision), numpy.mean(recall), numpy.mean(f1)))
print('\n'.join(lines))
def get_summary(self):
correct = 0
precision = numpy.zeros(self.alphabet.size())
recall = numpy.zeros(self.alphabet.size())
f1 = numpy.zeros(self.alphabet.size())
lines = []
# computing precision, recall, and f1
for i in range(self.alphabet.size()):
precision[i] = self.matrix[i,i] / sum(self.matrix[i,:])
recall[i] = self.matrix[i,i] / sum(self.matrix[:,i])
if precision[i] + recall[i] != 0:
f1[i] = 2 * precision[i] * recall[i] / (precision[i] + recall[i])
else:
f1[i] = 0
correct += self.matrix[i,i]
label = self.alphabet.get_label(i)
lines.append( '%s \tprecision %f \trecall %f\t F1 %f' %\
(label, precision[i], recall[i], f1[i]))
lines.append( '* Overall accuracy rate = %f' %(correct / sum(sum(self.matrix[:,:]))))
lines.append( '* Average precision %f \t recall %f\t F1 %f' %\
(numpy.mean(precision), numpy.mean(recall), numpy.mean(f1)))
return '\n'.join(lines)
def get_average_prf(self):
precision = numpy.zeros(self.alphabet.size())
recall = numpy.zeros(self.alphabet.size())
f1 = numpy.zeros(self.alphabet.size())
lines = []
# computing precision, recall, and f1
for i in range(self.alphabet.size()):
precision[i] = self.matrix[i,i] / sum(self.matrix[i,:])
recall[i] = self.matrix[i,i] / sum(self.matrix[:,i])
if precision[i] + recall[i] != 0:
f1[i] = 2 * precision[i] * recall[i] / (precision[i] + recall[i])
else:
f1[i] = 0
return numpy.mean(precision), numpy.mean(recall), numpy.mean(f1)
def get_accuracy(self):
correct = 0
precision = numpy.zeros(self.alphabet.size())
recall = numpy.zeros(self.alphabet.size())
f1 = numpy.zeros(self.alphabet.size())
lines = []
# computing precision, recall, and f1
for i in range(self.alphabet.size()):
precision[i] = self.matrix[i,i] / sum(self.matrix[i,:])
recall[i] = self.matrix[i,i] / sum(self.matrix[:,i])
if precision[i] + recall[i] != 0:
f1[i] = 2 * precision[i] * recall[i] / (precision[i] + recall[i])
else:
f1[i] = 0
correct += self.matrix[i,i]
label = self.alphabet.get_label(i)
lines.append( '%s \tprecision %f \trecall %f\t F1 %f' %\
(label, precision[i], recall[i], f1[i]))
return correct / sum(sum(self.matrix[:,:]))
def print_out(self):
"""Printing out confusion matrix along with Macro-F1 score"""
self.print_matrix()
self.print_summary()
def matrix_to_string(matrix, header=None):
"""
Return a pretty, aligned string representation of a nxm matrix.
This representation can be used to print any tabular data, such as
database results. It works by scanning the lengths of each element
in each column, and determining the format string dynamically.
the implementation is adapted from here
mybravenewworld.wordpress.com/2010/09/19/print-tabular-data-nicely-using-python/
Args:
matrix - Matrix representation (list with n rows of m elements).
header - Optional tuple or list with header elements to be displayed.
Returns:
nicely formatted matrix string
"""
if isinstance(header, list):
header = tuple(header)
lengths = []
if header:
lengths = [len(column) for column in header]
#finding the max length of each column
for row in matrix:
for column in row:
i = row.index(column)
column = str(column)
column_length = len(column)
try:
max_length = lengths[i]
if column_length > max_length:
lengths[i] = column_length
except IndexError:
lengths.append(column_length)
#use the lengths to derive a formatting string
lengths = tuple(lengths)
format_string = ""
for length in lengths:
format_string += "%-" + str(length) + "s "
format_string += "\n"
#applying formatting string to get matrix string
matrix_str = ""
if header:
matrix_str += format_string % header
for row in matrix:
matrix_str += format_string % tuple(row)
return matrix_str
# 标签和索引的相互映射
class Alphabet(object):
"""Two way map for label and label index
It is an essentially a code book for labels or features
This class makes it convenient for us to use numpy.array
instead of dictionary because it allows us to use index instead of
label string. The implemention of classifiers uses label index space
instead of label string space.
"""
def __init__(self):
self._index_to_label = {} # 下标:标签
self._label_to_index = {} # 标签:下标
self.num_labels = 0 # 下标数量
def __len__(self):
return self.size()
def __eq__(self, other):
return self._index_to_label == other._index_to_label and \
self._label_to_index == other._label_to_index and \
self.num_labels == other.num_labels
def size(self):
return self.num_labels
def has_label(self, label):
return label in self._label_to_index
def get_label(self, index):
"""Get label from index"""
if index >= self.num_labels:
raise KeyError("There are %d labels but the index is %d" % (self.num_labels, index))
return self._index_to_label[index]
def get_index(self, label):
"""Get index from label"""
if not self.has_label(label):
self.add(label)
return self._label_to_index[label]
def add(self, label):
"""Add an index for the label if it's a new label"""
if label not in self._label_to_index:
self._label_to_index[label] = self.num_labels
self._index_to_label[self.num_labels] = label
self.num_labels += 1
def json_dumps(self):
return json.dumps(self.to_dict())
@classmethod
def json_loads(cls, json_string):
json_dict = json.loads(json_string)
return Alphabet.from_dict(json_dict)
def to_dict(self):
return {
'_label_to_index': self._label_to_index
}
@classmethod
def from_dict(cls, alphabet_dictionary):
"""Create an Alphabet from dictionary
alphabet_dictionary is a dictionary with only one field
_label_to_index which is a map from label to index
and should be created with to_dict method above.
"""
alphabet = cls()
alphabet._label_to_index = alphabet_dictionary['_label_to_index']
alphabet._index_to_label = {}
for label, index in alphabet._label_to_index.items():
alphabet._index_to_label[index] = label
# making sure that the dimension agrees
assert(len(alphabet._index_to_label) == len(alphabet._label_to_index))
alphabet.num_labels = len(alphabet._index_to_label)
return alphabet
5.16 trainer.py
训练文件,也是主函数所在文件,函数内部就是调用上述文件定义的类和函数,最后对主函数的流程做一个阐述。
- 定义特征函数列表
- 选择分类器
- 加载各个$\textrm{config.py}$z中的各个参数
- 创建训练类
- 加载$\textrm{csv}$文件和$\textrm{json}$文件
- 生成特征文件
- 用特征文件和训练文件训练模型
- 用模型预测测试文件
- 整理,评估
#encoding: utf-8
import sys
sys.path.append("../")
import json
import pandas
from model_trainer.evalution import get_prediction, Evalution
from model_trainer.data_loader import load_train_data
from model_trainer.data_loader import load_test_data
from model_trainer.make_feature_file import Make_feature_file
from feature_functions import *
from classifier import *
class Trainer(object):
def __init__(self,
classifier, # 分类器
model_path, # 模型路径
feature_function_list, # 特征函数列表
train_feature_path, # 训练集的特征文件路径
test_feature_path, # 测试集的特征文件路径
test_result_path): # 测试集的结果文件路径
self.classifier = classifier
self.model_path = model_path
self.feature_function_list = feature_function_list
self.train_feature_path = train_feature_path
self.test_feature_path = test_feature_path
self.test_result_path = test_result_path
# 生成特征文件,调用make_feature_file中的Make_feature_file函数
'''
train_AuthorIdPaperIds: 训练集 KDD_Benchmark\data\dataset\train_set\Train.csv
test_AuthorIdPaperIds: 测试集 KDD_Benchmark\data\dataset\valid_set\Valid.csv
dict_coauthor: 字典,从coauthor.json读取生成
dict_paperIdAuthorId_to_name_aff: 字典,从paperIdAuthorId_to_name_and_affiliation.json读取生成
PaperAuthor: DataFrame,从PaperAuthor.csv中得到
Author: DataFrame,从Author.csv中得到
'''
def make_feature_file(self, train_AuthorIdPaperIds, test_AuthorIdPaperIds, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author):
# 打印提示字段
print(("-"*120))
print(("\n".join([f.__name__ for f in feature_function_list])))
print(("-" * 120))
print("make train feature file ...")
# 生成KDD_Benchmark\feature\train.feature 和 KDD_Benchmark\feature\train.feature.arff
Make_feature_file(train_AuthorIdPaperIds, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author, self.feature_function_list, self.train_feature_path)
print("make test feature file ...")
# 生成KDD_Benchmark\feature\test.feature 和 KDD_Benchmark\feature\test.feature.arff
Make_feature_file(test_AuthorIdPaperIds, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author, self.feature_function_list, self.test_feature_path)
# 通过特征文件和sklearn的库训练模型
def train_mode(self):
self.classifier.train_model(self.train_feature_path, self.model_path)
# 用训练好的模型和测试文件生成预测结果
def test_model(self):
self.classifier.test_model(self.test_feature_path, self.model_path, self.test_result_path)
# 最终测试的主函数流程
if __name__ == "__main__":
''' 特征函数列表 '''
feature_function_list = [
coauthor_1,
coauthor_2,
stringDistance_1,
stringDistance_2,
]
''' 分类器 '''
# 决策树,NB,等
# classifier = Classifier(skLearn_DecisionTree()) #决策树
classifier = Classifier(skLearn_NaiveBayes()) #朴素贝叶斯
# classifier = Classifier(skLearn_svm()) #支持向量机
# classifier = Classifier(skLearn_lr()) #逻辑回归
# classifier = Classifier(skLearn_KNN()) #k近邻算法(default k = 3)
# classifier = Classifier(sklearn_RandomForestClassifier()) #随机森林
# classifier = Classifier(skLearn_AdaBoostClassifier()) #集成学习
# classifier = Classifier(sklearn_VotingClassifier()) #投票分类(hard)
''' model path '''
model_path = config.MODEL_PATH
''' train feature_file & test feature_file & test result path '''
train_feature_path = config.TRAIN_FEATURE_PATH
test_feature_path = config.TEST_FEATURE_PATH
test_result_path = config.TEST_RESULT_PATH
''' Trainer '''
trainer = Trainer(classifier, model_path, feature_function_list, train_feature_path, test_feature_path, test_result_path)
''' load data '''
print("loading data...")
train_AuthorIdPaperIds = load_train_data(config.TRAIN_FILE) # 加载训练数据,Train.csv
test_AuthorIdPaperIds = load_test_data(config.TEST_FILE) # 加载测试数据,Valid.csv/Test.csv
# coauthor.json, 共作者数据,
dict_coauthor = json.load(open(config.COAUTHOR_FILE,"r",encoding="utf-8"))#, encoding="utf-8"
# paperIdAuthorId_to_name_and_affiliation.json,姓名和单位的复合数据
# (paperId, AuthorId) --> {"name": "name1##name2", "affiliation": "aff1##aff2"}
dict_paperIdAuthorId_to_name_aff \
= json.load(open(config.PAPERIDAUTHORID_TO_NAME_AND_AFFILIATION_FILE,"r",encoding="utf-8"))#, encoding="utf-8"
# 使用pandas加载csv数据
PaperAuthor = pandas.read_csv(config.PAPERAUTHOR_FILE) # 加载 PaperAuthor.csv 数据
Author = pandas.read_csv(config.AUTHOR_FILE) # 加载 Author.csv 数据
print("data is loaded...")
# 为训练和测试数据,抽取特征,分别生成特征文件
trainer.make_feature_file(train_AuthorIdPaperIds, test_AuthorIdPaperIds, dict_coauthor, dict_paperIdAuthorId_to_name_aff, PaperAuthor, Author)
# 根据训练特征文件,训练模型
trainer.train_mode()
# 使用训练好的模型,对测试集进行预测
trainer.test_model()
# 对模型的预测结果,重新进行整理,得到想要的格式的预测结果
get_prediction(config.TEST_FEATURE_PATH, config.TEST_RESULT_PATH, config.TEST_PREDICT_PATH)
''' 评估,(预测 vs 标准答案)'''
gold_file = config.GOLD_FILE
pred_file = config.TEST_PREDICT_PATH
cmd = "python evalution.py %s %s" % (gold_file, pred_file)
os.system(cmd)
分析报告
最终成果参见报告:$\textrm{KDD Report}$
最终源代码参加$\textrm{GitHub}$项目:$\textrm{ECNU-2021-Spring-Data-Mining-KDD}$
Author@Kuroko
GitHub@SuperKuroko
LeetCode@kuroko177
Last Modified: 2021-06-02 11:58
